
A serverless-friendly vector database in your hands
FlechasDB is a serverless-friendly vector database1.
What is a Vector Database? by Pinecone. It surprised me that there seemed no Wikipedia page exists for vector databases.
Features
- Save/Load database files to/from Amazon S3 buckets
- Run on Amazon Linux 22
More features are coming!
Amazon Linux 2 is the standard operating system of AWS Lambda instances as of this writing.
How to get started
The core library flechasdb and its Amazon S3 extension flechasdb-s3 are available from the following GitHub repositories respectively:
You can use flechasdb and flechasdb-s3 on AWS Lambda by integrating them into a custom Lambda runtime for Amazon Linux 2.
Since both flechasdb and flechasdb-s3 are written in Rust, cargo-lambda may be helpful.
You can find some examples of deploying Lambda functions using flechasdb and flechasdb-s3 with AWS Cloud Development Kit (CDK) in the following GitHub repositories,
- https://github.com/codemonger-io/mumble/tree/main/cdk
- https://github.com/codemonger-io/mumble-embedding/tree/main/cdk
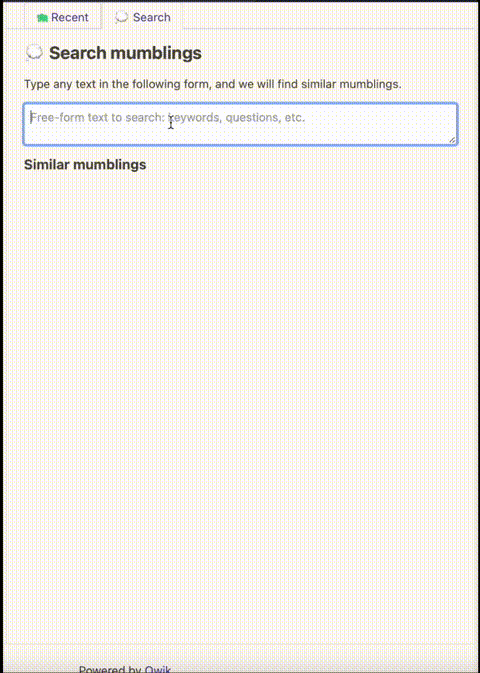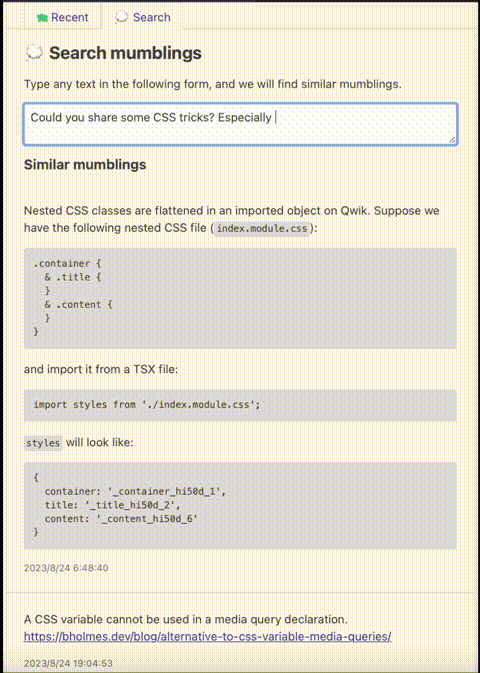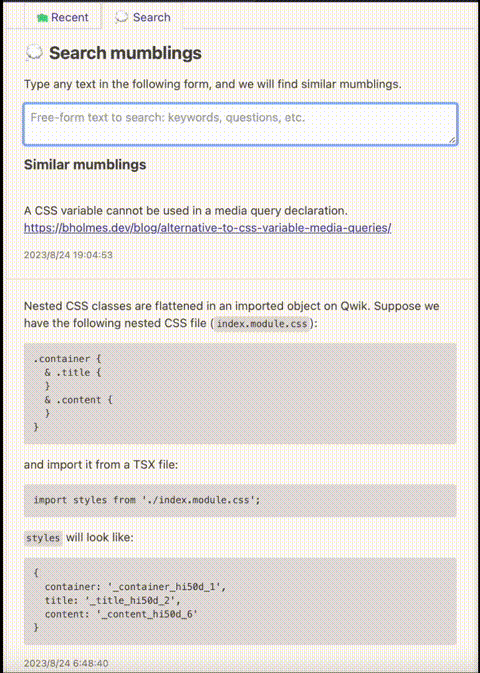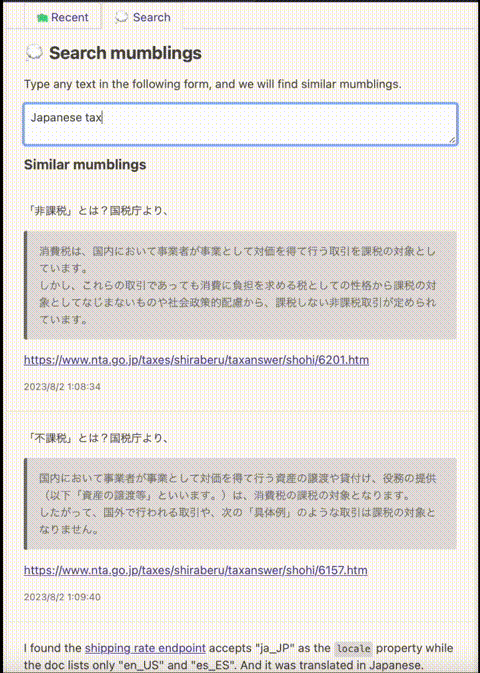
FlechasDB in action
Mumble uses FlechasDB to power its search feature. It builds the FlechasDB database from OpenAI's embeddings calculated for posts (mumblings) and stores the database files in an Amazon S3 bucket. You can try it on Kikuo's Mumble profile.
Background
There are better products and services out there: Pinecone, Milvus, etc.
Faiss is a de facto library for vector search and is much more performant and reliable than flechasdb.
To be honest, I, Kikuo, reinvented this wheel just out of my curiosity:
- how IVFPQ indexing works3
- how to utilize auto-vectorization by Rust's optimizer4
- how to write async Rust
However, I believe FlechasDB may be one of the cheapest solutions for small projects. So why not consider FlechasDB for your feasibility study of vector databases?
Product Quantizers for k-NN Tutorial Part 2 - https://mccormickml.com/2017/10/22/product-quantizer-tutorial-part-2/
Taking Advantage of Auto-Vectorization in Rust - https://www.nickwilcox.com/blog/autovec/