アクセスログの分析(1. マスキング編)
2022-11-02
このブログ投稿では私のウェブサイトのCloudFrontアクセスログからどのようにして個人データを減らしているかを紹介します。 これはアクセスログ分析に関するシリーズの最初の投稿です。
背景
私にとって、私のウェブサイトの閲覧者を知ることは重要です。 誰が見ているのかを特定する必要はありませんが、大まかにどのような閲覧者たちなのかは知りたいところです。 このウェブサイトはAmazon CloudFront (CloudFront)のDistributionを介して配信しており、CloudFrontがアクセスログを記録しています。 ということでこれらのアクセスログを分析することが閲覧者を理解*する最初のステップです。 CloudFrontがどのパラメータをアクセスログに含むかをコントロールすることはできませんが、我々の集めるアクセスログがGeneral Data Protection Regulation (GDPR)[1]*2に確実に準拠するようにしなければなりません。 このブログでは、個人データを減らすためにCloudFrontアクセスログを変換するAWS上の私のアーキテクチャを紹介します。
* Googleアナリティクスを提案する方もいらっしゃるかもしれませんが、Googleアナリティクスは私が必要とするよりはるかに詳細な(不要な)情報を集めてしまいます。 また、Googleアナリティクスやその類を採用することで不気味なCookieを導入したくもありません。 GoogleアナリティクスはGDPR準拠に関する課題も抱えています[2]。
*2 このウェブサイトで集める情報を用いて皆さんに何か危害を加えることができるとは思いませんが、何にせよ不要な情報は集めるべきではありません。
CloudFrontアクセスログはGDPRに準拠している?
答えはダメそうです。 CloudFrontアクセスログの個々のカラムでは個人を特定することはできないかもしれません。 しかし、CloudFrontアクセスログ内のIPアドレスやUser-Agentなどのカラムを組み合わせると、個人を特定*してその人をトラッキングすることができてしまいそうです。 こちらの記事[3]によると、CloudFrontアクセスログを長期間保管したい場合は最低限そこに含まれるIPアドレスからある程度のビットを落とす必要がありそうです。 ここで紹介することは本質的にはその記事[3]に記載されていることと同じです。
* ここで「特定」するとは、その人の名前、電子メール、連絡先などを知ることではなく、ある人をその人が正確に誰であるかを知ることなく他の人から区別するということです。
免責
私は法曹の者ではなく、 これは法的なアドバイスではありません。
私のアーキテクチャの概要
以下の図にAWS上の私のアーキテクチャを示します。
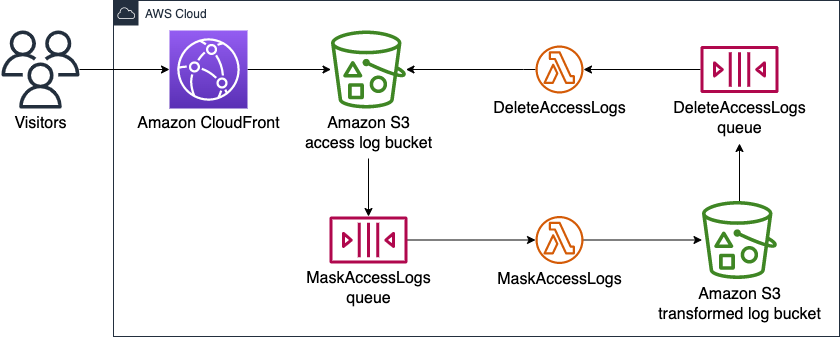
ワークフローは以下の通りです。
Amazon CloudFrontがアクセスログファイルをAmazon S3 access log bucketに保存。Amazon S3 access log bucketがPUTイベントをMaskAccessLogs queueに送信。MaskAccessLogs queueがMaskAccessLogsを呼び出し。MaskAccessLogsが新しいアクセスログファイルを変換し、結果をAmazon S3 transformed log bucketに保存。Amazon S3 transformed log bucketがPUTイベントをDeleteAccessLogs queueに送信。DeleteAccessLogs queueがDeleteAccessLogsを呼び出し。DeleteAccessLogsがオリジナルのアクセスログファイルをAmazon S3 access log bucketから削除。
このウェブサイトのために上記のアーキテクチャ*を確保するAWS Cloud Development Kit (CDK)スタックが私のGitHubレポジトリにあります(特に、cdk-ops/lib/access-logs-etl.ts)。 CDK特有の課題がありましたが、詳しくは節「CloudFrontアクセスログ用のS3バケットを特定する」をご参照ください。
以下の小節では上図の各コンポーネントを解説します。
* 私のGitHubレポジトリの最新コードはデータウェアハウスなどの追加の機能も含んでいます。
Amazon CloudFront
Amazon CloudFrontは我々のウェブサイトのコンテンツをAmazon CloudFrontのDistributionを通じて配信しており、アクセスログをAmazon S3 access log bucketに保存します。
Amazon S3 access log bucket
Amazon S3 access log bucketはAmazon CloudFrontが作成したアクセスログを保管するAmazon S3 (S3)バケットです。
このバケットはアクセスログファイルがPUTされるとMaskAccessLogs queueにイベントを送信します。
MaskAccessLogs queue
MaskAccessLogs queueはAmazon Simple Queue Service (SQS)のキューでMaskAccessLogsを呼び出します。
Amazon S3 access log bucketはアクセスログファイルがPUTされるとこのキューにイベントを送信します。
Amazon S3 access log bucketからMaskAccessLogsに直接イベントを届けることもできますが、そうはしませんでした。
理由については節「なぜS3バケットとLambda関数を直接つながないのか?」をご参照ください。
MaskAccessLogs
MaskAccessLogsはAWS Lambda (Lambda)関数で、Amazon S3 access log bucketのアクセスログを変換します。
この関数はCloudFrontアクセスログ内のIPアドレス(c-ipとx-forwarded-for)をマスクします。
以下を落とし(ゼロで埋め)ます。
- IPv4アドレス32ビット中の8最下位ビット(LSB)
- IPv6アドレス128ビット中の96 LSB
この関数はアクセスログレコードの元々の順番を保つために行番号を含む新しいカラムも導入します。
この関数は変換結果をAmazon S3 transformed log bucketに保存します。
Amazon S3 access log bucketはアクセスログファイルをフラットに展開しますが、この関数はアクセスログレコードの年月日に対応するフォルダ階層を作成します。
このフォルダ構造は後続のステージ*が特定の日付のアクセスログをバッチで処理する際に役立ちます。
この関数の実装は私のGitHubレポジトリ(cdk-ops/lambda/mask-access-logs/index.py)にあります。
* 今後のブログ投稿で、アクセスログをデータウェアハウスにロードする後のステージを解説する予定です。
Amazon S3 transformed log bucket
Amazon S3 transformed log bucketはMaskAccessLogsが変換したアクセスログを格納するS3バケットです。
このバケットは変換したアクセスログファイルがPUTされるとDeleteAccessLogs queueにイベントを送信します。
DeleteAccessLogs queue
DeleteAccessLogs queueはSQSキューで、DeleteAccessLogsを呼び出します。
Amazon S3 transformed log bucketは変換されたアクセスログファイルがPUTされるとこのキューにイベントを送信します。
Amazon S3 transformed log bucketからDeleteAccessLogsに直接イベントを届けることもできますが、そうはしませんでした。
理由については節「なぜS3バケットとLambda関数を直接つながないのか?」をご参照ください。
DeleteAccessLogs
DeleteAccessLogsはLambda関数で、MaskAccessLogsが変換しAmazon S3 transformed log bucketに保存済みのアクセスログファイルをAmazon S3 access log bucketから削除します。
この関数の実装は私のGitHubレポジトリ(cdk-ops/lambda/delete-access-logs/index.py)にあります。
まとめ
このブログでは、CloudFrontアクセスログを長期間保存することはGDPRに違反する可能性があることを学びました。 そして、CloudFrontアクセスログから個人データを減らすためのAWSアーキテクチャを紹介しました。
今後のブログ投稿では、Amazon Redshift Serverlessを用いたデータウェアハウスにアクセスログを読み込む方法を紹介する予定です。
補足
CloudFrontアクセスログ用のS3バケットを特定する
CloudFrontのDistribution(cloudfront.Distribution (Distribution))を確保する際に、ログを有効化した上でアクセスログ用のS3バケットを省略した場合、CDKが代わりにバケットを確保してくれます。
これを行った場合の問題点はCDKが確保するS3バケットの所在を我々で管理できないということです。
残念ながら、L2 Construct(Distribution)はアクセスログ用のS3バケット名を取得する手軽な方法を用意しておらず、CloudFront DistributionのL1レイヤー(cloudfront.CfnDistribution (CfnDistribution))まで潜らなければなりません。
アクセスログ用のS3バケット名を抽出するには次のように辿る必要があります。Distribution → CfnDistribution → CfnDistribution#distributionConfig → CfnDistribution.DistributionConfigProperty#logging → CfnDistribution.LoggingProperty#bucket。
以下はDistributionからアクセスログ用のS3バケット名を抽出するためのステップです。
-
distribution: Distributionと仮定。 -
distribution.node.defaultChildをCfnDistributionにキャスト。cfnDistribution = distribution.node.defaultChild as cloudfront.CfnDistribution; -
cfnDistribution.distributionConfigを解決。cfnDistribution.distributionConfigをCfnDistribution.DistributionConfigPropertyとして単純に参照することはできません。なぜならIResolvableかもしれないからです。stack = distribution; distributionConfig = cfnDistribution.distributionConfig as CfnDistribution.DistributionConfigProperty; -
distributionConfig.loggingを解決。distributionConfig.loggingもIResolvableかもしれないのでCfnDistribution.LoggingPropertyとして単純に参照することはできません。loggingConfig = distributionConfig.logging as CfnDistribution.LoggingProperty; -
S3バケットのロジカルID(CloudFormationテンプレート内におけるID)を
loggingConfig.bucketから抽出。 私の観察とCDKのソースコードによれば、loggingConfig.bucketはS3バケットのリージョナルドメイン名を取得する組み込み関数Fn::GetAttです。 ということでS3バケット名を参照する前にロジカルIDを抽出します。bucketRef = loggingConfig.bucket; getAtt = bucketRef; bucketLogicalId = getAtt; -
bucketLogicalIdで示されるS3バケット名を参照。accessLogsBucketName = bucketLogicalId;
上記ステップの実装は私のGitHubレポジトリ(cdk/lib/contents-distribution.ts#L122-L154)にあります。
とはいえ、自分でアクセスログ保存先のS3バケットを用意する方がよっぽど楽でしょうね・・・
なぜS3バケットとLambda関数を直接つながないのか?
S3バケットに対する変更がLambda関数をトリガーするようにS3バケットとLambda関数をイベント通知で直接接続することもできます。
やり方については"Using AWS Lambda with Amazon S3," AWS Lambda Developer Guide[4]を参照してください。
ところが、私のAWSアーキテクチャではご覧のとおり、S3バケットとLambda関数を直接接続する代わりに追加のSQSキューを間に挟むことにしました(Amazon S3 access log bucket → MaskAccessLogs queue → MaskAccessLogsおよびAmazon S3 transformed log bucket → DeleteAccessLogs queue → DeleteAccessLogs)。
一段複雑になりますが、何か問題が起きた際にLambda関数の呼び出しを簡単にON/OFFできるようになります。
さもなくば、イベントの流れを切断するためにLambda関数からイベントトリガーを削除しなければなりません。
参考
- General Data Protection Regulation (GDPR) Compliance Guidelines - https://gdpr.eu
- Is Google Analytics (3 & 4) GDPR-compliant? [Updated] - https://piwik.pro/blog/is-google-analytics-gdpr-compliant/
- Anonymize CloudFront Access Logs - https://cloudonaut.io/anonymize-cloudfront-access-logs/
- "Using AWS Lambda with Amazon S3," AWS Lambda Developer Guide - https://docs.aws.amazon.com/lambda/latest/dg/with-s3.html