Analyzing access logs (1. Masking)
2022-11-02
This blog post shares how I have reduced personal data in CloudFront access logs on my website. This is the first post of a series about access log analysis.
Background
It is crucial to me to know the audience of my website. I do not need to identify who is viewing but want to see an overview of them. This website is delivered via an Amazon CloudFront (CloudFront) distribution, and CloudFront records access logs. So analyzing those access logs is the first step for me to understand the audience*. Although we cannot control which parameters CloudFront includes in access logs, we have to ensure our collection of access logs is compliant with the General Data Protection Regulation (GDPR)[1]*2. In this blog post, I show you my architecture on AWS to transform CloudFront access logs to reduce personal data.
* One may suggest Google Analytics, but Google Analytics collects far more detailed (unnecessary) information than I need. And I neither want to introduce creepy Cookies by adopting Google Analytics and likes. Google Analytics also has difficulties in GDPR compliance[2].
*2 Although I do not think I could do anything harmful to you with the information collected on this website, we should not collect unnecessary information anyway.
Are CloudFront access logs GDPR compliant?
The answer is likely no. Individual columns in CloudFront access logs may not identify a single person. However, if we combine columns like IP address and user-agent in CloudFront access logs, we likely could identify* a single person and track that person. According to this article[3], we should at least drop certain bits from IP addresses in CloudFront access logs if we want to store them for long. What I introduce here is essentially the same as what the article[3] describes.
* To "identify" here does not mean to know one's name, email, contact, etc., but to distinguish one person from others without knowing exactly who it is.
Disclaimer
I am not a lawyer. This is not legal advice.
Overview of my architecture
The following diagram shows the overview of my architecture on AWS.
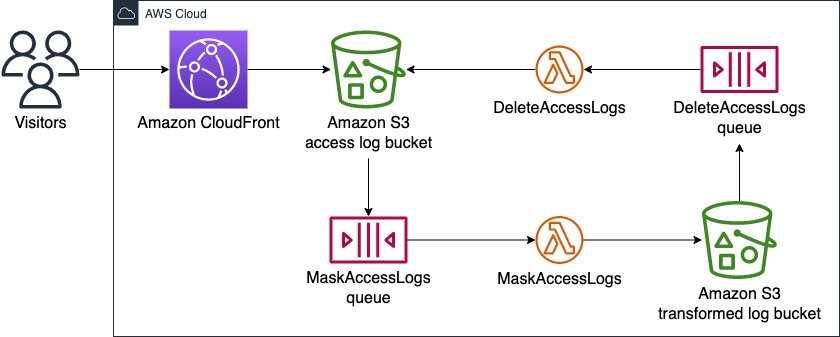
The workflow is described below,
Amazon CloudFrontsaves an access logs file inAmazon S3 access log bucket.Amazon S3 access log bucketsends a PUT event toMaskAccessLogs queue.MaskAccessLogs queueinvokesMaskAccessLogs.MaskAccessLogstransforms the new access logs file and saves the results inAmazon S3 transformed log bucket.Amazon S3 transformed log bucketsends a PUT event toDeleteAccessLogs queue.DeleteAccessLogs queueinvokesDeleteAccessLogs.DeleteAccessLogsdeletes the original access logs file fromAmazon S3 access log bucket.
You can find a AWS Cloud Development Kit (CDK) stack that provisions the above architecture* for this website on my GitHub repository; specifically cdk-ops/lib/access-logs-etl.ts. I have had a CDK-specific issue there, and please refer to the Section "Identifying the S3 bucket for CloudFront access logs" for more details.
The following subsections describe each component on the above diagram.
* The latest code on my GitHub repository contains extra features like a data warehouse.
Amazon CloudFront
Amazon CloudFront distributes the contents of our website through an Amazon CloudFront distribution and saves access logs in Amazon S3 access log bucket.
Amazon S3 access log bucket
Amazon S3 access log bucket is an Amazon S3 (S3) bucket that stores access logs created by Amazon CloudFront.
This bucket sends an event to MaskAccessLogs queue when an access logs file is PUT into this bucket.
MaskAccessLogs queue
MaskAccessLogs queue is an Amazon Simple Queue Service (SQS) queue that invokes MaskAccessLogs.
Amazon S3 access log bucket sends an event to this queue when an access logs file is PUT into the bucket.
We could directly deliver events from Amazon S3 access log bucket to MaskAccessLogs, but I have not.
Please refer to the Section "Why don't you directly connect an S3 bucket and Lambda function?" for why I have avoided it.
MaskAccessLogs
MaskAccessLogs is an AWS Lambda (Lambda) function that transforms access logs in Amazon S3 access log bucket.
This function masks IP addresses, c-ip and x-forwarded-for, in the CloudFront access logs.
It drops (fills with zeros)
- 8 least significant bits (LSBs) out of 32 bits from an IPv4 address
- 96 LSBs out of 128 bits from an IPv6 address
This function also introduces a new column of row numbers to retain the original order of the access log records.
This function saves transformed results in Amazon S3 transformed log bucket.
While Amazon S3 access log bucket spreads access logs files flat, this function creates a folder hierarchy corresponding to the year, month, and day of access log records.
This folder structure will help a subsequent stage* process access logs on a specific date in a batch.
You can find the implementation of this function in cdk-ops/lambda/mask-access-logs/index.py on my GitHub repository.
* An upcoming blog post will describe the later stage that loads access logs onto a data warehouse.
Amazon S3 transformed log bucket
Amazon S3 transformed log bucket is an S3 bucket that stores access logs transformed by MaskAccessLogs.
This bucket sends an event to DeleteAccessLogs queue when a transformed access logs file is PUT into this bucket.
DeleteAccessLogs queue
DeleteAccessLogs queue is an SQS queue that invokes DeleteAccessLogs.
Amazon S3 transformed log bucket sends an event to this queue when a transformed access logs file is PUT into the bucket.
We could directly deliver events from Amazon S3 transformed log bucket to DeleteAccessLogs, but I have not.
Please refer to the Section "Why don't you directly connect an S3 bucket and Lambda function?" for why I have avoided it.
DeleteAccessLogs
DeleteAccessLogs is a Lambda function that deletes an access logs file from Amazon S3 access log bucket, which MaskAccessLogs has transformed and saved in Amazon S3 transformed log bucket.
You can find the implementation of this function in cdk-ops/lambda/delete-access-logs/index.py on my GitHub repository.
Wrap-up
In this blog post, we learned storing CloudFront access logs for long may violate the GDPR. Then I showed you my AWS architecture to reduce personal data from CloudFront access logs.
In an upcoming blog post, I will introduce how to load access logs onto a data warehouse backed by Amazon Redshift Serverless.
Appendix
Identifying the S3 bucket for CloudFront access logs
If we omit the S3 bucket for access logs while enabling logging when provisioning a CloudFront distribution (cloudfront.Distribution (Distribution)), the CDK allocates one on our behalf.
A drawback of this is that we cannot manage the identity of the S3 bucket that the CDK provisions.
Unfortunately, as the L2 construct (Distribution) provides no handy way to obtain the name of the S3 bucket for access logs, we have to dig the L1 layer of a CloudFront distribution (cloudfront.CfnDistribution (CfnDistribution)).
To extract the name of the S3 bucket for access logs, we have to chase Distribution → CfnDistribution → CfnDistribution#distributionConfig → CfnDistribution.DistributionConfigProperty#logging → CfnDistribution.LoggingProperty#bucket.
Here are steps to extract the name of the S3 bucket for access logs from Distribution:
-
Suppose you have
distribution: Distribution. -
Cast
distribution.node.defaultChildasCfnDistribution:cfnDistribution = distribution.node.defaultChild as cloudfront.CfnDistribution; -
Resolve
cfnDistribution.distributionConfig. You cannot simply referencecfnDistribution.distributionConfigasCfnDistribution.DistributionConfigPropertybecause it may be anIResolvable:stack = distribution; distributionConfig = cfnDistribution.distributionConfig as CfnDistribution.DistributionConfigProperty; -
Resolve
distributionConfig.logging. You can neither simply referencedistributionConfig.loggingasCfnDistribution.LoggingPropertybecause it also may be anIResolvable:loggingConfig = distributionConfig.logging as CfnDistribution.LoggingProperty; -
Extract the logical ID (ID in the CloudFormation template) of the S3 bucket from
loggingConfig.bucket. According to my observation and the CDK source code,loggingConfig.bucketis an intrinsic functionFn::GetAttthat obtains the regional domain name of the S3 bucket. So we extract the logical ID before referencing the name of the S3 bucket:bucketRef = loggingConfig.bucket; getAtt = bucketRef; bucketLogicalId = getAtt; -
Reference the name of the S3 bucket specified by
bucketLogicalId:accessLogsBucketName = bucketLogicalId;
You can find the implementation of the above steps in cdk/lib/contents-distribution.ts#L122-L154 on my GitHub repository.
By the way, bringing your own S3 bucket as the access log destination shall be much easier.
Why don't you directly connect an S3 bucket and Lambda function?
You can directly wire an S3 bucket and Lambda function with event notifications so that changes in the S3 bucket trigger the Lambda function.
Please refer to "Using AWS Lambda with Amazon S3," AWS Lambda Developer Guide[4] for how to do it.
However, as you can see on my AWS architecture, I have decided to insert an extra SQS queue between an S3 bucket and Lambda function instead of directly connecting them: Amazon S3 access log bucket → MaskAccessLogs queue → MaskAccessLogs, and Amazon S3 transformed log bucket → DeleteAccessLogs queue → DeleteAccessLogs.
This additional complexity allows you to easily turn on/off the invocation of a Lambda function in case there is any problem.
Otherwise, you have to delete the event trigger from a Lambda function to cut the event flow.
Reference
- General Data Protection Regulation (GDPR) Compliance Guidelines - https://gdpr.eu
- Is Google Analytics (3 & 4) GDPR-compliant? [Updated] - https://piwik.pro/blog/is-google-analytics-gdpr-compliant/
- Anonymize CloudFront Access Logs - https://cloudonaut.io/anonymize-cloudfront-access-logs/
- "Using AWS Lambda with Amazon S3," AWS Lambda Developer Guide - https://docs.aws.amazon.com/lambda/latest/dg/with-s3.html